ChatGPT 的自白
作者:
最后更新于 | 最初发布于 | 分类: 搜索引擎优化之无类可分
最近一段时间关于 AI 的话题很热,我也想说说我的看法,但是想再等等,等资料再充分一点,数据再多一点,再来谈,不过最近有不少网友的文字让我不等不写下此文,他们有不少是臆想,瞎猜,或者根据自己的过往经验来猜测 ChatGPT 是怎么回事。其实 ChatGPT 既然是可以对话的,那么何不来直接问问它自己呢?
下面是我同 ChatGPT 的一些对话,可以了解一下它自己的自白。
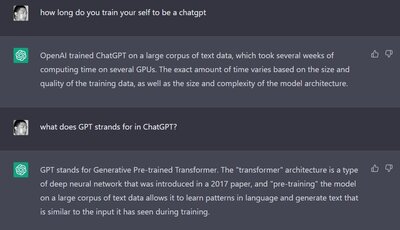 这是问它,训练时间,基本上对于每一个语料,它训练学习的时间是以几周为数量的。
这是问它,训练时间,基本上对于每一个语料,它训练学习的时间是以几周为数量的。
顺便再问了一下 GPT 的具体含义。
接下来我的问题是有关 ChatGPT 计划之前运行了多久。得到的答案是2018年开始,基本上到2022年12月就开始给公众尝鲜了。
就是四年的时间在练习和训练。

紧跟着我问它,它的竞争对手有哪些?看看它的回复。
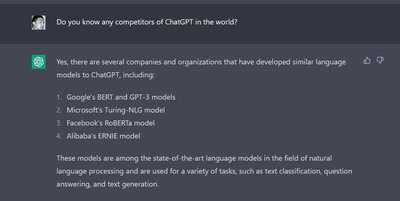 其实就四家在它看来是竞争对手的,值得注意的,像有人提到的 百度,或者其它都没有提。
其实就四家在它看来是竞争对手的,值得注意的,像有人提到的 百度,或者其它都没有提。
- Google's BERT and GPT-3 models
- Microsoft's Turing-NLG model
- Facebook's RoBERTa model
- Alibaba's ERNIE model
了解到这四家之后,我问它有没有比较过同他们的优劣差别,它的答案很官方,就说各有差异,侧重不通,也个=各有弱点。
于是,我就问它它的弱点是什么?
 我觉得这就很重要,比如它提到了四点,包括缺乏背景,训练数据中的偏见,缺乏常识,缺乏原创性思维。这都很重要,这些弱点会让它的答案中出现重大偏差,所以用户在使用它的答案时,需要自己判断对错,而不能盲目相信。
我觉得这就很重要,比如它提到了四点,包括缺乏背景,训练数据中的偏见,缺乏常识,缺乏原创性思维。这都很重要,这些弱点会让它的答案中出现重大偏差,所以用户在使用它的答案时,需要自己判断对错,而不能盲目相信。
然后我问了一堆有关中文语料的构成,不同语料库之间是否会存在翻译并共享等等的问题。它的答案很长,我也常识用了不同的方式来问它。

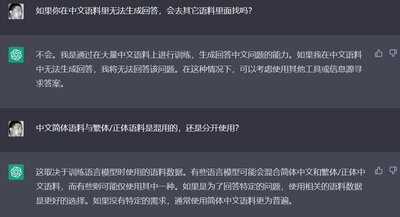
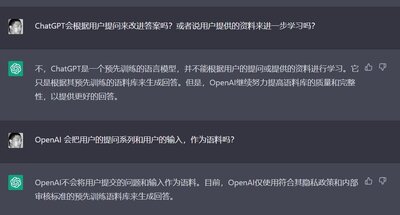 基本上得到的答案,就是它的各种语言的语料库都是单独训练,它不会在找不到中文答案的时候,去英文里面找,再翻译过来。
基本上得到的答案,就是它的各种语言的语料库都是单独训练,它不会在找不到中文答案的时候,去英文里面找,再翻译过来。
这个答案其实我是不太相信的,虽然是它自己说的,但是总是感觉它应该可以翻译,并且在统一的知识库中形成答案。
让我再来问问它。

OpenAI训练的语言模型是多语言的,拥有多种语言的语料库。模型在训练时会根据语料库的语言进行分类,但是最终形成的模型是统一的,并且模型能够自动识别语言并选择合适的语言模型进行回答。 训练后的模型具有逻辑判断能力和语言表达能力,并且它也拥有知识储备。这些知识储备是从语料库中学习到的,并通过模型的训练进行了组织和整合。因此,模型可以回答各种知识性问题,如历史、地理、科学等。
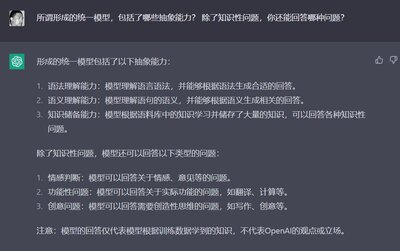
形成的统一模型包括了以下抽象能力:
语法理解能力:模型理解语言语法,并能够根据语法生成合适的回答。
语义理解能力:模型理解语句的语义,并能够根据语义生成相关的回答。
知识储备能力:模型根据语料库中的知识学习并储存了大量的知识,可以回答各种知识性问题。
除了知识性问题,模型还可以回答以下类型的问题:
情感判断:模型可以回答关于情感、意见等的问题。
功能性问题:模型可以回答关于实际功能的问题,如翻译、计算等。
创意问题:模型可以回答需要创造性思维的问题,如写作、创意等。
注意:模型的回答仅代表模型根据训练数据学到的知识,不代表OpenAI的观点或立场。
这个答案就比较符合我在同 ChatGPT 交流中的感受了。
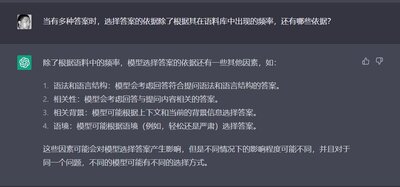
接下来又提出了一个同样的问题给出不同答案的原理是怎样的?它的答案放在下面,请大家自己判断其真实性。